NowInOpenHarmony上架笔记之再起新征程
前言
时隔一个国庆假期,我在抛去一切技术焦虑尽情的享受假期之后也是回来重振旗鼓,准备开始开展NowInOpenHarmony的后端重构之旅了。这个项目我不能放弃,这是当下我距离正式上架最近的一个项目,而且我也已经成果实现了针对于后端的docker容器化部署,同时有了之前踩坑的经历我会用更加直接切中要害的方式去进行调整。
新版OpenHarmony官网的内容变化
重构的第一件事肯定是要去审视一下我们新的数据源————新版NowInOpenHarmony官网,看看它和旧版相比有哪些变化,以及这些变化对我们项目的影响。记得在国庆前我看到openharmony官网的更新的时候我是有点绝望的因为我是压根没有看到原来那个咨询页面和博文页面依旧存在,只看到了新的首页。所以我先去整体的浏览一遍看看有没有可以作为新版数据源的页面。
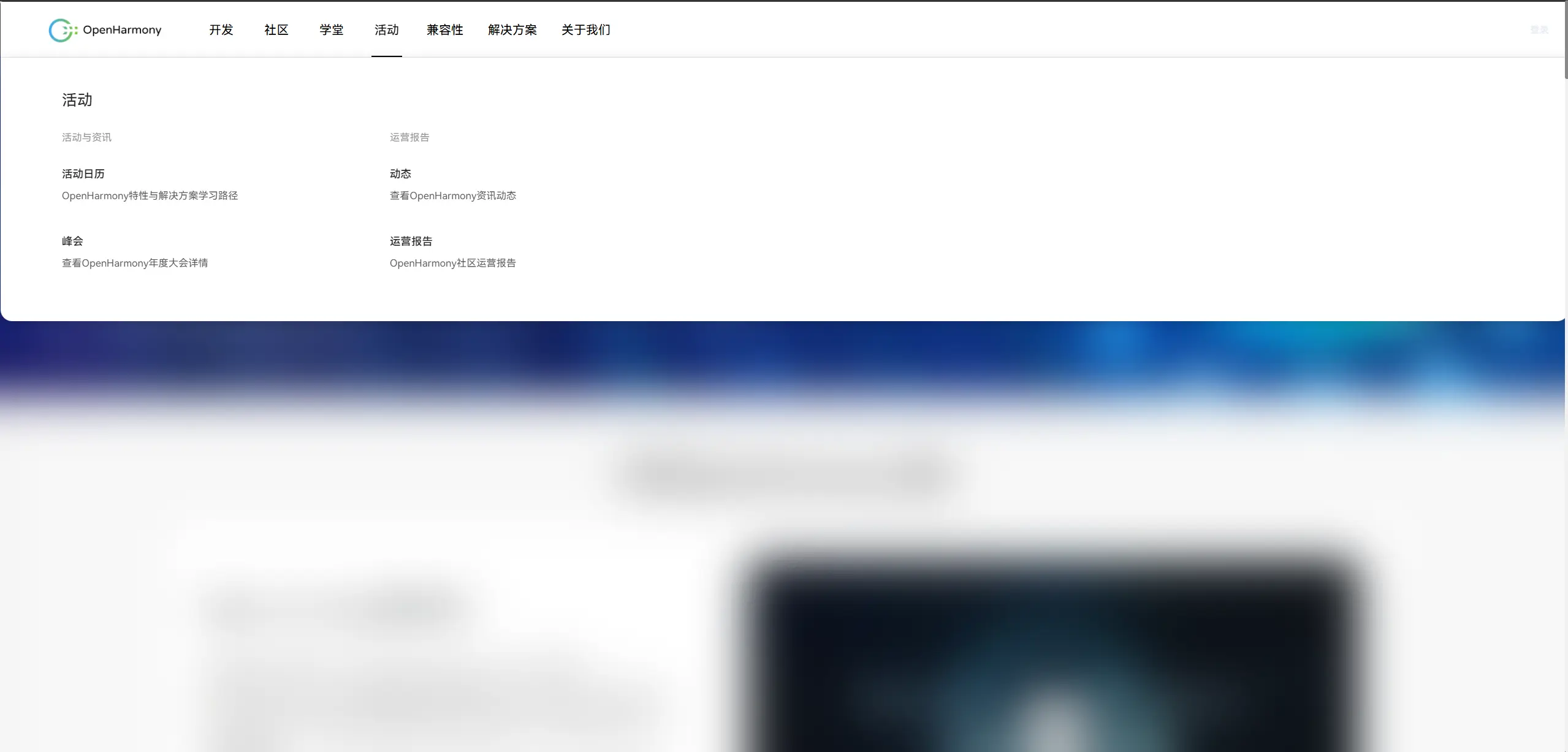
在浏览的时候我看到了导航栏的这个分栏,我瞬间捕捉到了关键词“咨询”和“动态”,我立刻点进去看,不看不知道一看吓一跳,原来这就是原来那个网页!!!
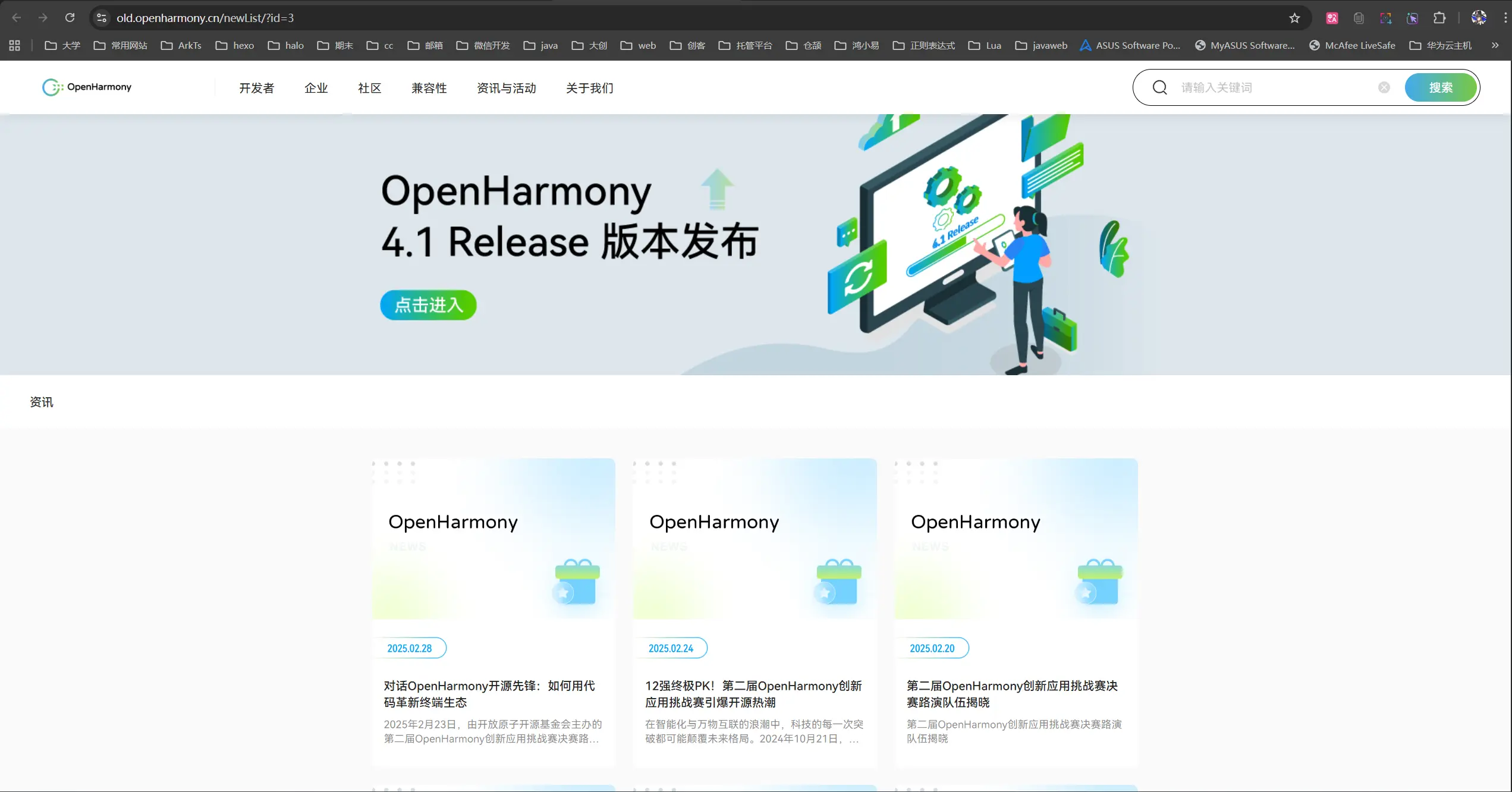
卧槽原来它并没有被废弃,只是从原来的根域名被新主页给挤压到old前缀的子域名了,太好了,不仅不用去寻找新的数据源,还不用重新针对新的页面去进行重构了。

重构后端
这里当然还是先请出我们的老朋友CC啦。
让CC的新对话熟悉现在的后端逻辑
在和AI连续的对话构建一个项目固然是方便毕竟上下文连贯AI的记忆也是很连贯的,但也是会有死钻牛角尖的情况出现,AI也很容易陷入到自己的惯性思维中不能自拔,最后越改越屎所以我一定是要开一个新对话去进行编程的。
对于一个新的对话,熟悉当前的项目结构是很重要的,对于CC来说他是有一个独特的优势在于/init指令可以一键让CC对当前的项目有一个最初始的印象,了解项目的架构同时去编写或是更新项目的claude.md文件。
在执行/init之后还不够,由于我们所需要的是修改一个爬虫逻辑中的一个细节所以我还是决定让CC进一步的去阅读并理解一下三个爬虫的逻辑以及工作流程,并告诉他我们接下来的工作主要是围绕这三个文件去进行展开的。
1 | 现在请你着重关注关注后端服务中针对于openharmony官网囊咨询页面的爬虫 @services/openharmony_crawler.py 博文页面爬虫 @services/openharmony_blog_crawler.py 还有轮播图爬虫 @services/openharmony_image_crawler.py 我们接下来的工作重点在于针对于这三个爬虫的重构升级,现在请你先仔细阅读并给我理清三个爬虫的逻辑,暂时不要修改任何代码 |
重构过程
文件重命名
我首先让CC先帮我针对于官网的咨询页爬虫进行一下重命名,因为当初他是第一个开发的就没有很规范的命名,而py这个东西又是解释型语言,不同文件之间调用有基本上是跑起来解释到那里才知道有问题,所以我就直接用CC去进行重构还是更快捷一些。

嗯,就还挺爽的。
old子域名重构
这一块的话我得向CC阐述一下来龙去脉并给他新的API。所以首先我需要先去官网进行一下抓包找到之前用于获取目标网页的那个api接口,我希望它只是将原来的这套网页代码的基地址换成了新的子域名而不是说进行了完整的重构。这样我就只需要更换一下API就好了。
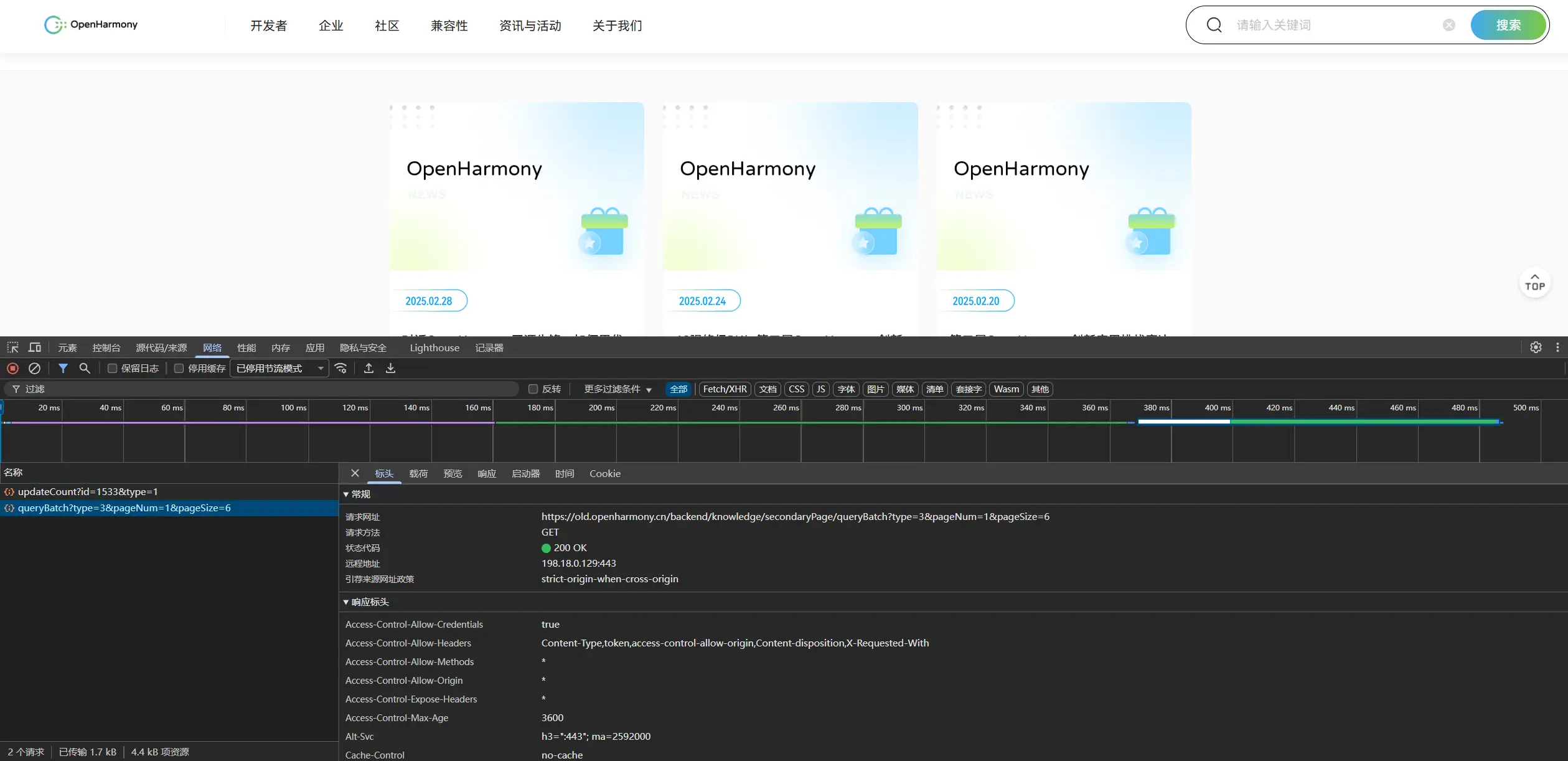
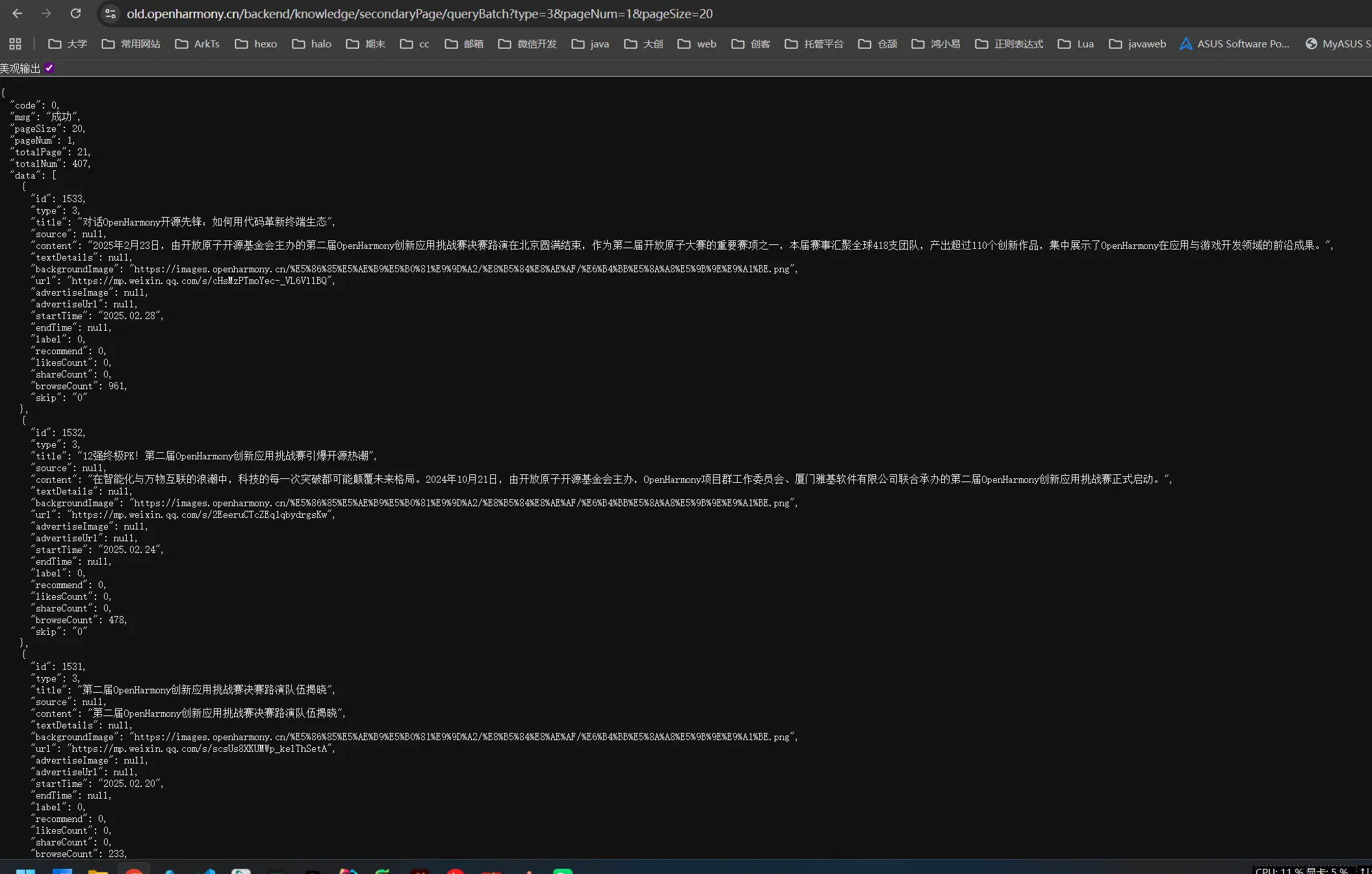
1 | // https://old.openharmony.cn/backend/knowledge/secondaryPage/queryBatch?type=3&pageNum=1&pageSize=20 |
1 | // https://old.openharmony.cn/backend/knowledge/secondaryPage/queryBatch?type=3&pageNum=1&pageSize=2 |
啊啊啊太感动了哥们,完全没变,和我猜想的一样。
1 | 现在的任务是这样的,当前的三个爬虫都是在官网重构之前的,现在我们的数据源根地址变成了https://old.openharmony.cn/像是 @services/openharmony_news_crawler.py 中所用的数据源API api_url = f"{self.base_url}/backend/knowledge/secondaryPage/queryBatch?type=3&pageNum={page_num}&pageSize={page_size}"这一段就要变成https://old.openharmony.cn/backend/knowledge/secondaryPage/queryBatch?type=3&pageNum=1&pageSize=300 请以此类推,在保持原有模板字符串拼接URL的基础上将基地址进行更换 |
等了一会儿终于是跑完了,全部修改完成,现在让我试试吧。
啊啊啊牛逼成功了,接下来就该去打包了。
打包上线
本地打包
有了上一次的经验我决定先将当前项目在本地打包成tar文件,因为服务器的CPU只有两核打包确实是太慢了,所以我现在开始让cc帮我去进行打包。
在等待cc执行玩之后我还是遇到了那个问题,我无法单独打包为tar,总是会直接被打包为.tar.gz格式,我尝试先去和CC交涉一下,看看是不是因为CC理解错了。
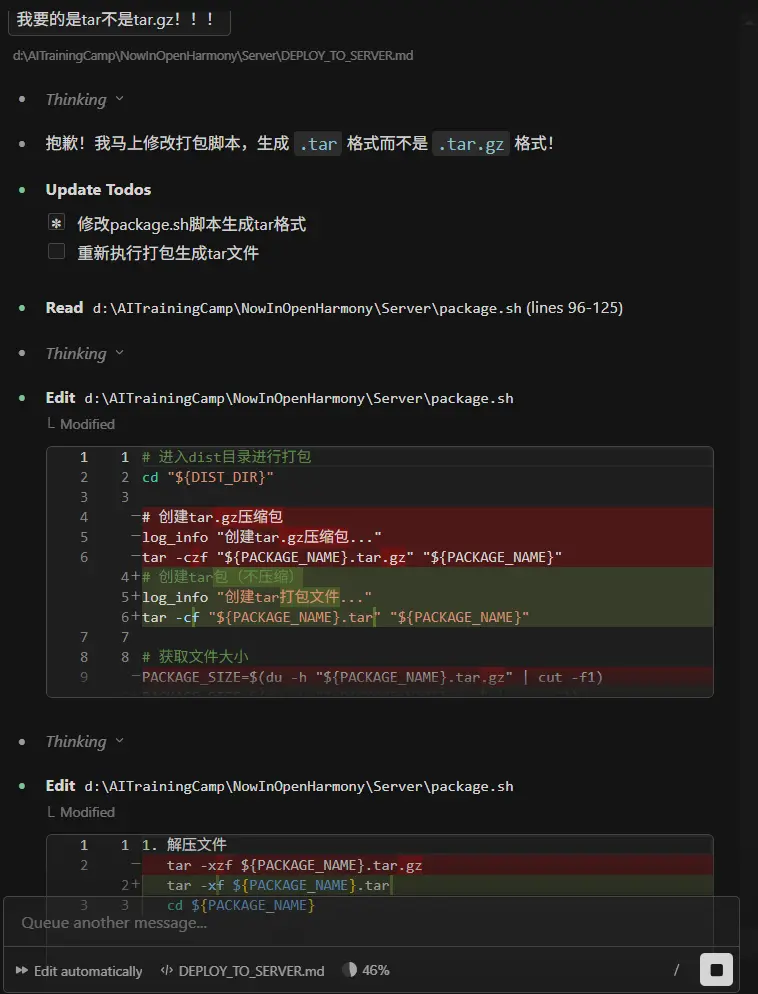
奥,原来还真是CC写错了。

云端部署镜像
嘶,到了云端我才发现我好像理解错了,我只记得上次错在了导入镜像时需要的是tar不是tar.gz但是这次我直接选择tar包进行镜像导入的时候却还是报错了。
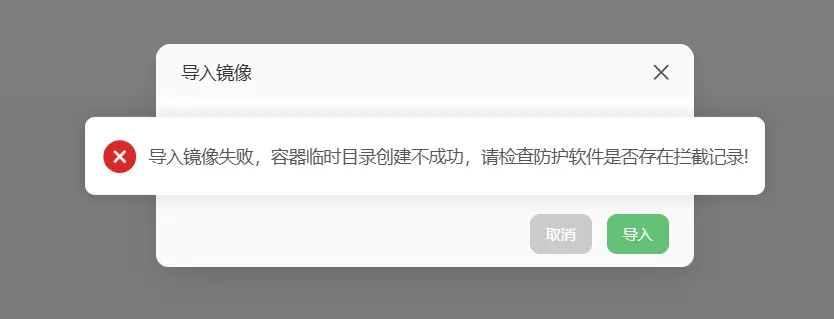
enm,我先给豆包看看吧。

奥,纯粹的打包成tar文件是不够的我们还需要用docker save来去导出标准的镜像包文件。

原来是这个原因。那我还是老老实实的去用命令行在云端构建吧。
又开始了这个漫长的构建过程。
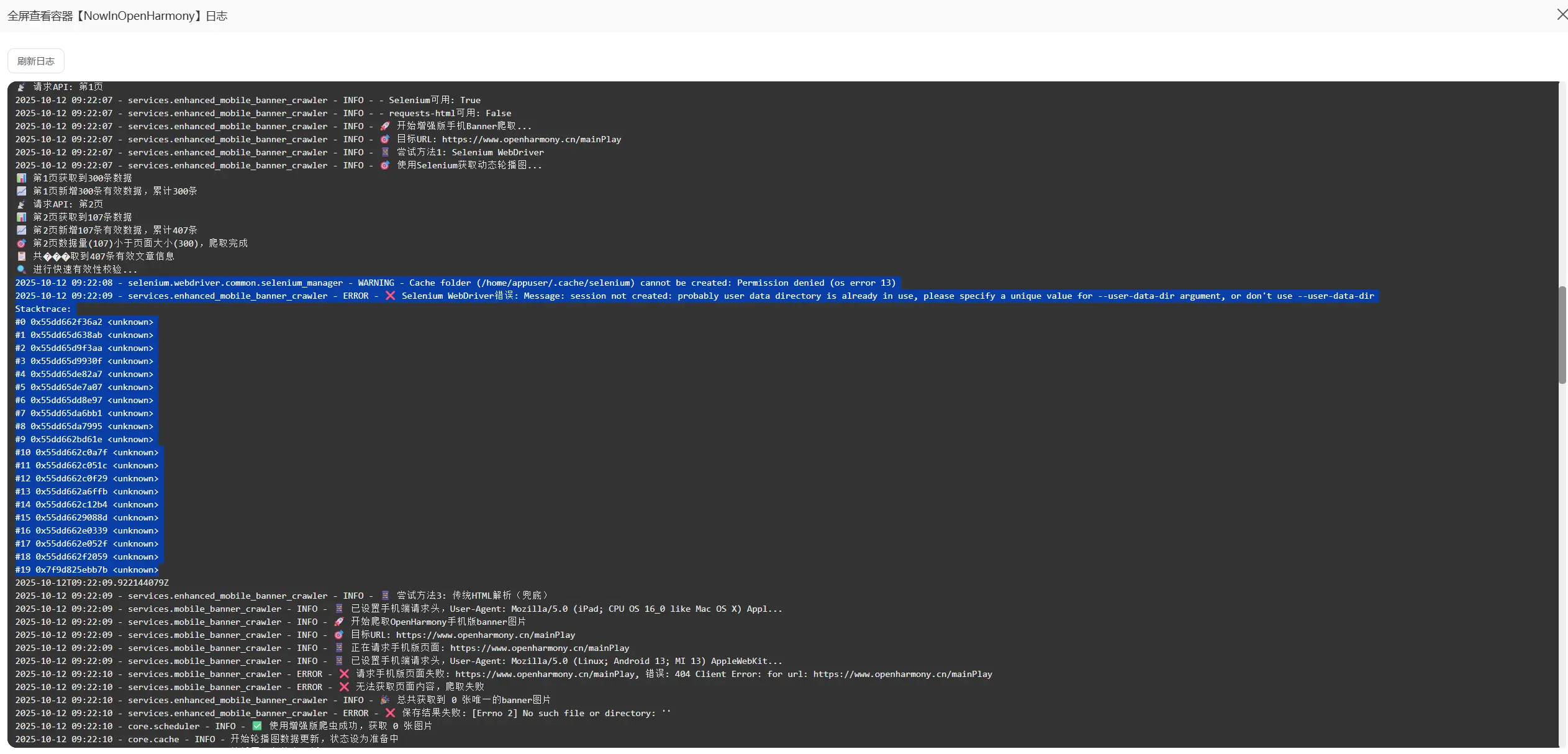

仔细观察日志发现了问题,原来是之前的爬虫修改过程有遗漏,还漏了几个基地址还是原来的老地址没有更新所以导致了404。
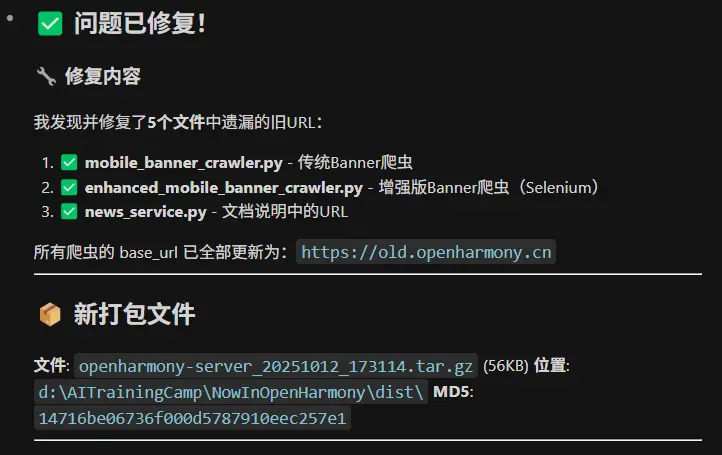
轮播图爬取问题
在经历了漫长的斗争之后,现在剩下的问题就在于轮播图接口始终是无法使用的状态,之前报过一个奇怪的错,再让CC修复了之后本地测试轮播图接口也是正常的,现在就是不知道为什么在远程部署后始终是无法访问。
当然我有一个推测是因为远程的处理器不如本地的好导致咨询的爬取占用了主要的资源导致轮播图爬虫的爬取被放到了后面,所以看起来像是轮播图的爬虫没有爬到数据。所以我决定先去等待一会儿,等第一轮爬取完全结束之后再去访问轮播图接口。
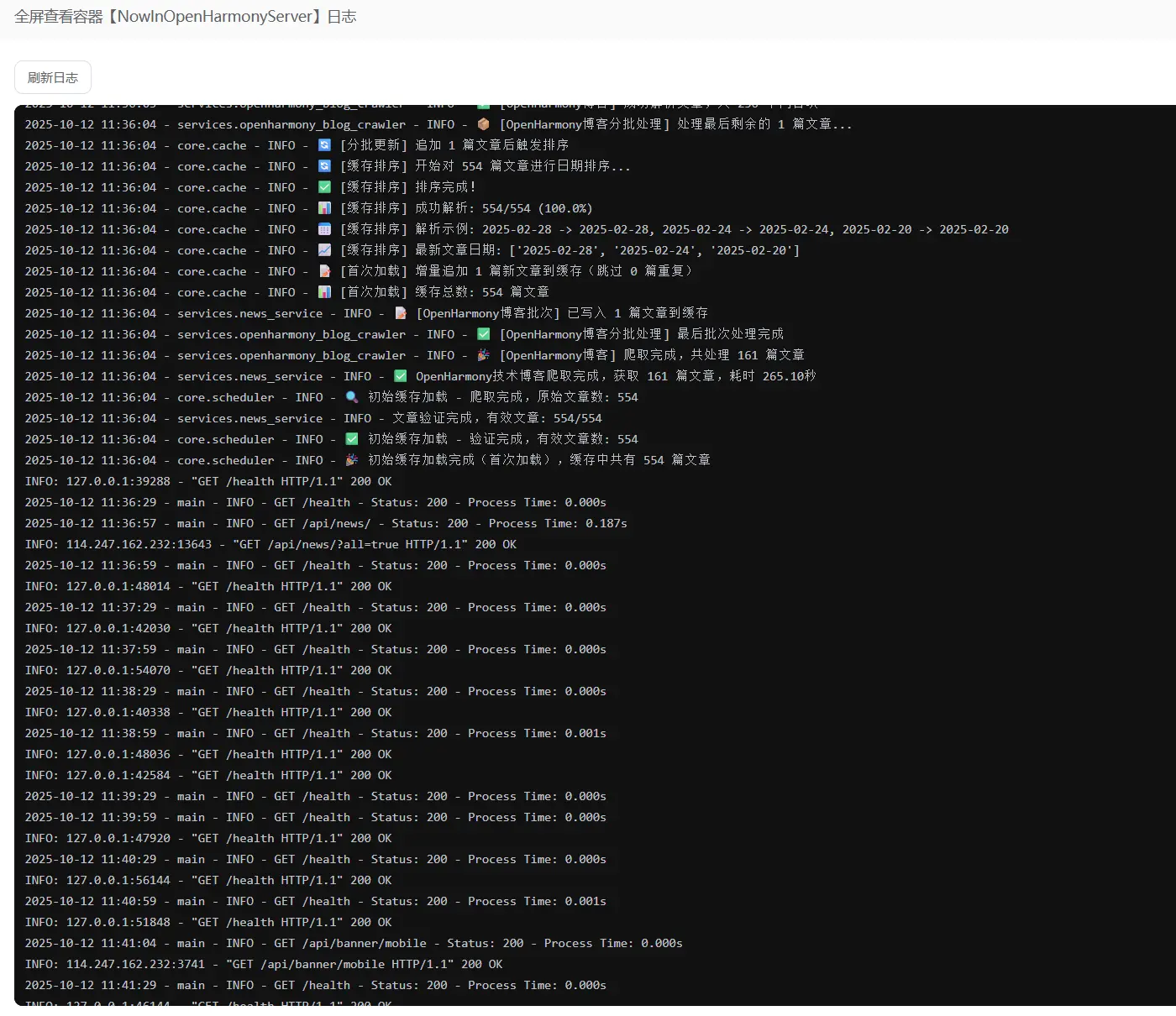
已经全部结束了但是依旧没有数据。
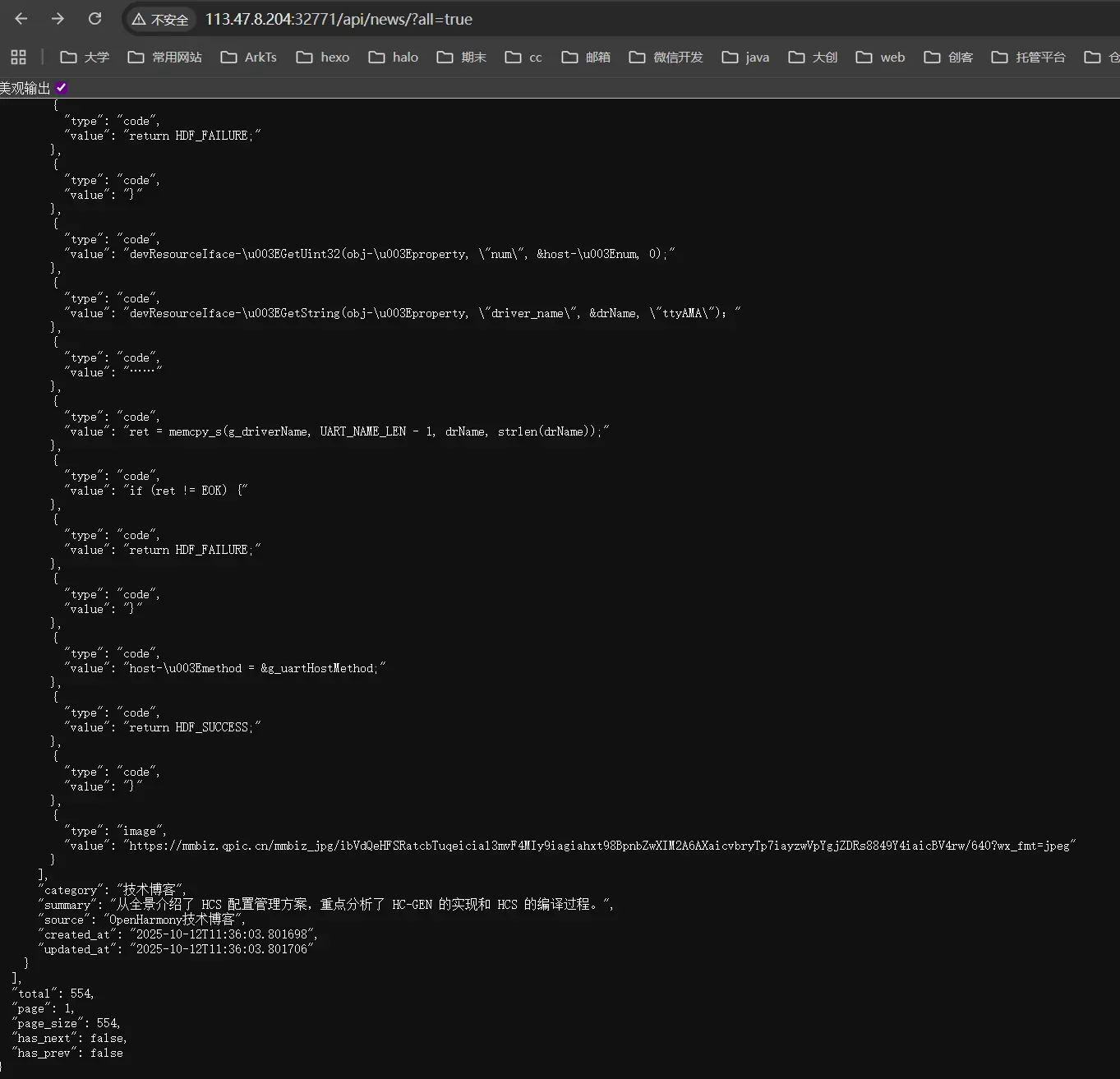
新闻接口是正常的。所以我现在怀疑就是因为Selenium在Docker容器中无法启动Chrome浏览器导致的。
在更新了最新一版的镜像文件之后我再次去进行了尝试,但是依旧是报了和之前相同的错误。
1 | 2025-10-13 11:52:51 - services.enhanced_mobile_banner_crawler - ERROR - ❌ Selenium WebDriver错误: Message: session not created: probably user data directory is already in use, please specify a unique value for --user-data-dir argument, or don't use --user-data-dir |
这里就说明了是因为使用selenium进行动态爬取时因为远程并没有谷歌浏览器以及浏览器的驱动程序导致了无法启动。我思考的解决方案有两种:一是直接将谷歌浏览器以及驱动程序下载到服务器上,二是更换动态爬取的方式。
更换codex
额,中间出了一点小状况导致我的CC401了,在和佳澎经过了一段长久的讨论之后我换成了codex,使用gpt5来去继续辅助我的工作。
我决定先去将上面的博文喂给它去弥补一下当前的工作状态。


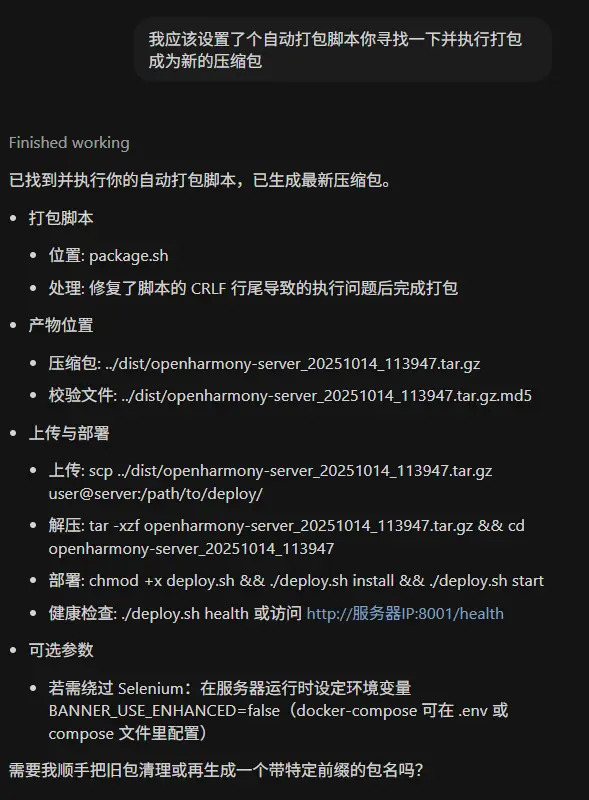
好好好,“顺手”你GPT5还是有点狂傲在里面的,算然确实是顺手的事,但Claude可不会这么说。
对于这个需求来说GPT5的high模式使用体感和Claude很类似,插件的便捷程度和界面的美观程度更胜于Claude,等我再多用一用再去进行评价吧,现在先再次部署进行轮播图接口的测试。
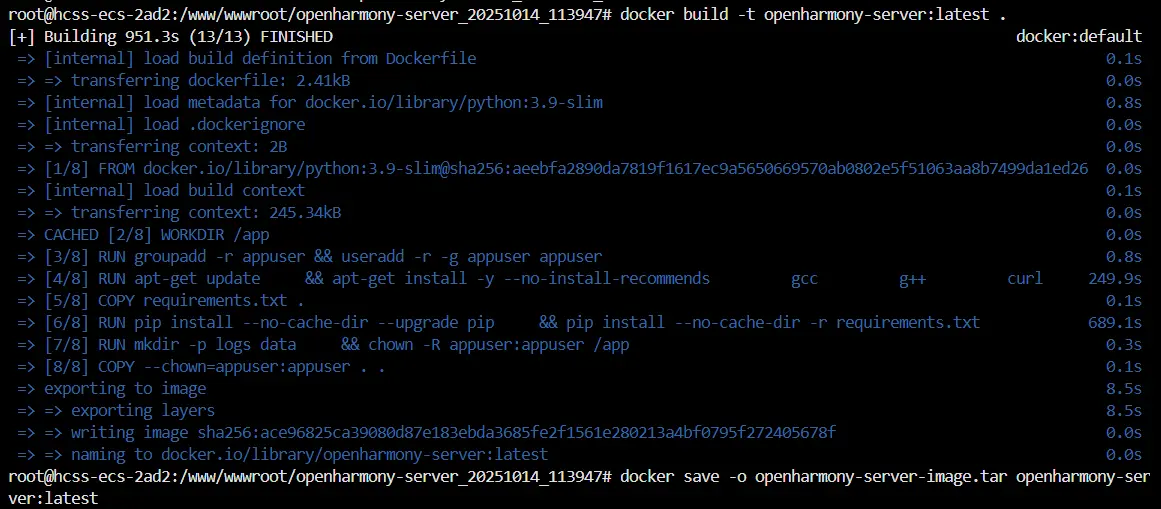
果然还是没有办法一帆风顺吗。再打包并且部署了最新版本的代码之后依旧出现了熟悉的报错。
1 | 2025-10-14 04:11:21 - services.enhanced_mobile_banner_crawler - WARNING - ⚠️ 首次启动Chrome失败: Message: session not created: probably user data directory is already in use, please specify a unique value for --user-data-dir argument, or don't use --user-data-dir |
1 | 谢谢反馈,问题复现点明确了:Selenium 仍报 “user data directory is already in use”,且传统解析对 Nuxt 动态页拿不到图片。我已就两处关键点做了代码级修复,并重新打包好一份可直接部署的包。 |
如果说这一次的尝试再次失败我就要开始针对于轮播图爬虫开始进行重构。
让我先进行一下新镜像的部署工作。
随后查看日志
1 | 113.47.8.204 |
还是失败了,我本打算直接开始去进行重构,但是考虑到Selenium与ChromeDriver是当下比较主流的工具所以我还是考虑再去上网搜索一下解决方案。
我找到了很多,Selenium的官方文档中也有介绍,所以我决定先去尝试一下这些方式。
从这些文章中我了解到Selenium与ChromeDriver是当下浏览器自动化爬虫还有测试等应用场景的主流王者。(应该能解决吧~)
这一次GPT5又提出了一个新的方案,这个新的方案是通过添加一个兜底机制,利用 Nuxt 状态解析兜底:解析页面里的 window.__NUXT__ 预渲染 JSON,直接提取 banner 图地址(对这种站点通常有效),避免 JS 执行。
1 | 看日志点:现在容器还是在用本地 Chromium/Chromedriver(日志里出现 “使用Chromedriver: /usr/bin/chromedriver”),并未启用远程 WebDriver;而传统解析对 Nuxt 动态页拿不到图。所以这次要落地远程 WebDriver 方案,让增强版走独立浏览器容器。 |
如果这一次成功了的话我就会考虑去除前面的方式,但仔细阅读它给出的解决方案之后我认为核心还是在于远程WebDriver,但还是先试一试吧,不试一试怎么知道呢。
1 | 113.47.8.204 |
好吧依旧失败了,现在尝试一下独立浏览器容器,当然我的前提肯定是不能在额外购置服务器,最好是直接在这个服务器上实现,我将会让GPT带着我去做,一步一步的。
1 | 看到了,还是在用本地 Chromedriver。我们直接按远程 WebDriver 落地,保证增强版能跑起来。给你两套可执行方案,按你当前“单容器(宝塔)”场景优先用方案A。 |
一下是我所需要执行的命令,让我来总结一下:
1 | docker network create ohnet || true |
1 | docker rm -f selenium 2>/dev/null || true |
1 | docker run -d --name selenium --network ohnet -p 4444:4444 --shm-size=2g --restart unless-stopped selenium/standalone-chromium:latest |
1 | until curl -sf http://127.0.0.1:4444/status | grep -q '"ready":true'; do echo "Waiting for Selenium remote WebDriver on :4444 ..."; sleep 2; done |
1 | docker rm -f NIOHServer 2>/dev/null || true |
1 | docker run -d --name NIOHServer --network ohnet -p 32776:8001 --shm-size=1g -e TZ=Asia/Shanghai -e BANNER_USE_ENHANCED=true -e SELENIUM_REMOTE_URL=http://selenium:4444/wd/hub -e SELENIUM_USE_USER_DATA_DIR=false openharmony-server:latest |
1 | curl -s http://127.0.0.1:4444/status |
1 | curl -s http://127.0.0.1:32776/health |
1 | curl -s -X POST "http://127.0.0.1:32776/api/banner/crawl?use_enhanced=true" |
1 | curl -s "http://127.0.0.1:32776/api/banner/status" |
1 | curl -s "http://127.0.0.1:32776/api/banner/mobile" |
1 | docker logs -f --tail=200 NIOHServer | grep -E "远程WebDriver|WebDriver|Selenium|使用Chromedriver|Banner|轮播图|enhanced" -n --color=always |
ok以上就是需要去执行的命令,现在我正在逐一执行,现在执行到了第三步。然后正在拉取 selenium/standalone-chromium 的镜像。这个过程比较长,刚好用来回顾一下这套解决方式。
我们所需要解决的核心问题在于,
主要集中在以下几件事:
- 浏览器环境可控化:把 WebDriver 从宿主机剥离,使用独立容器的固定版本,避免系统升级/驱动不匹配。
- 资源与稳定性:扩大 /dev/shm,避免长页面截图/滚动导致的崩溃;容器限额可控,防止互相“抢资源”。
- 网络连通性:容器间直连可预期,避免容器→宿主的网关差异(172.17.0.1 不同环境不一定可达)。
- 可观测性:通过“是否打印远程WebDriver日志”“/status”就绪检查,快速定位问题。
- 回退策略:一键切回非增强版(不依赖 Selenium),确保业务不中断。
我们的解决方案回顾:
- 自定义网络 ohnet,保证 API 容器与浏览器容器在同一网络内互通。
- 浏览器容器:selenium/standalone-chromium:latest 暴露 4444,提供标准远程 WebDriver。
- API 容器:通过
SELENIUM_REMOTE_URL=http://selenium:4444/wd/hub直连,不再依赖本地 chromedriver。
验证口径:
GET http://127.0.0.1:4444/status返回"ready": true后再重启/启动 API 容器。docker logs -f NIOHServer日志出现“使用远程WebDriver”,且不再打印本地 chromedriver 路径。- 访问
GET /api/banner/mobile与GET /api/banner/status,图片数量、最近抓取状态正常。
易踩坑与处理:
- /dev/shm 太小:为浏览器容器加
--shm-size=2g。 - 容器互通失败:确保两容器都在 ohnet;不要一个在 bridge、一个在 ohnet。
- 172.17.0.1 不通:优先方案A(容器内网直连)。若必须方案B,改宿主内网/公网IP 并放行防火墙。
- 镜像版本漂移:生产环境建议固定 tag(例如
selenium/standalone-chromium:122.0)。
应急回退(不用 Selenium 的非增强版):
1 | docker rm -f NIOHServer || true |
1 | docker run -d --name NIOHServer --network ohnet -p 32776:8001 --shm-size=1g \ |
后面我会继续执行剩余步骤,并记录 Banner 抓取成功率、耗时以及日志关键词(远程WebDriver/Chromedriver)对比,验证这套方案的稳定性提升是否达到预期。
1 | 2025-10-14 20:21:24 - root - INFO - 日志系统初始化完成 |
芜湖!!!卧槽这次日志总算是没问题了!!!
这样一来我就可以访问一下我的接口了,啊啊啊啊一定要没问题啊。
1 | http://113.47.8.204:32776/api/banner/mobile |
1 | { |
卧槽牛逼!!!成功了我再去测试一下其他接口。
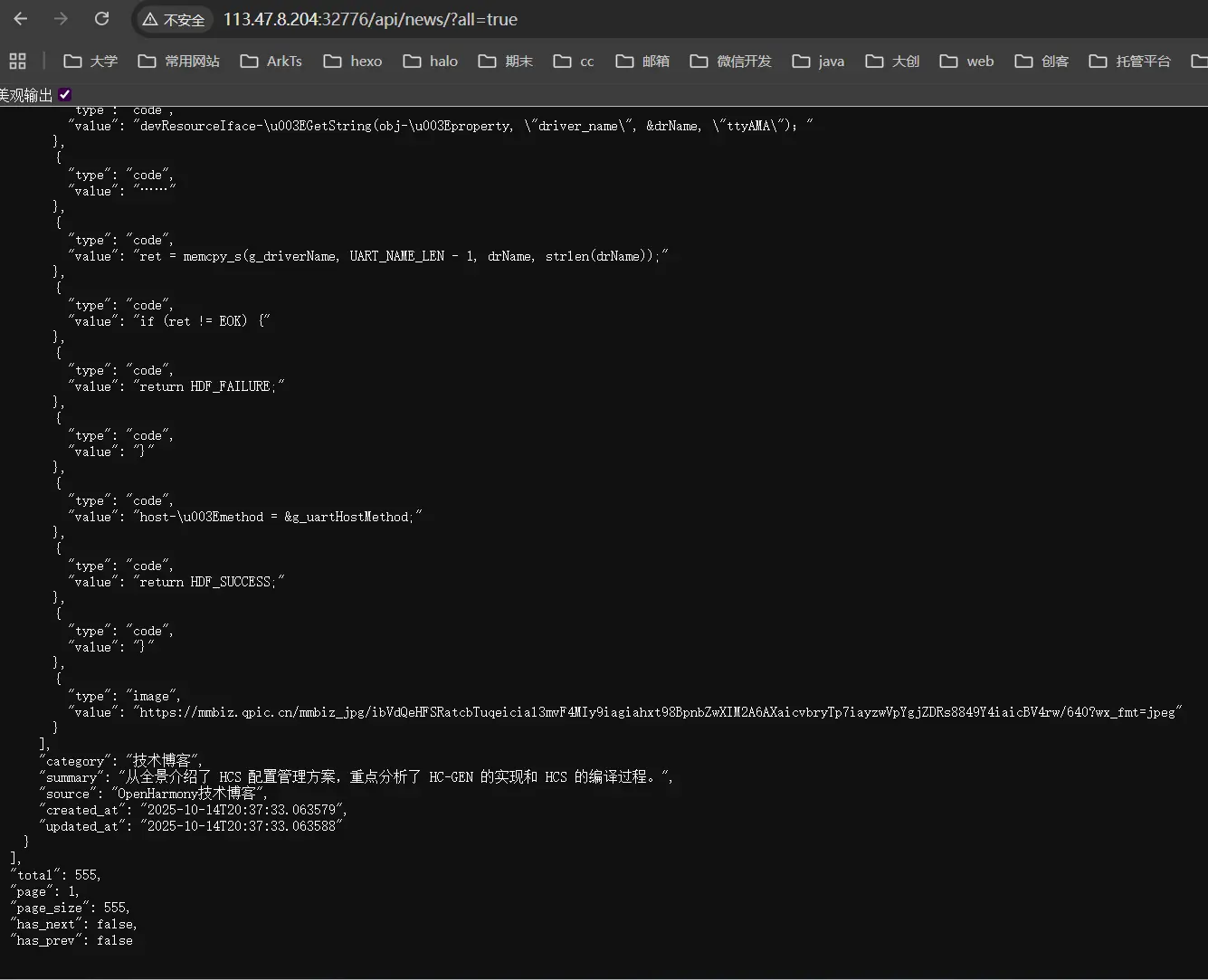
nbnb。这样一来我明天就可以开始真正的修改我的客户端基地址了。

CPU负载问题
在昨天顺利解决了我们的容器部署问题以及服务器WebDriver失效的问题之后,我本来以为万事大吉了就没有再管他,结果今天我上宝塔面板一看发现卧槽2核CPU持续性的维持在100%,连短暂的掉到99% 98%都没有出现,我赶紧关停了两个docker容器,服务器的CPU占用率终于是降下来了。我对于服务器的经验并不多,我也不确定这种情况是否正常,所以我决定先给GPT看看。
在GPT生成回复的过程中我也是上网去进行了一下检索。
这种现象是明显不正常的,有可能是死循环代码,内存泄漏,不合理的先乘除配置,为优化的数据库查询,第三方API调用超时堆积,DDoS攻击,爬虫滥用等等很多的情况,这些都可能会导致我的服务器CPU跑满的情况。
这并不是直接购买一个新CPU可以解决的问题,我平常仅仅运行我博客网站的Nginx的过程中CPU占用率仅维持在4%左右,所以说明它基本上将两个核的CPU资源全都耗尽了,我怀疑的问题是我的爬虫程序运行时开了很多的线程去进行爬取,在本地的多核CPU运行起来并不是什么负担,但是在服务器上的2核小CPU上去运行就是一个巨大的负担了。
让我们先来看看GPT的建议。
1 | 结论与现状 |
GPT给出的观点和我的观点一致,这并非常态,理论上来讲我们的程序只应该是在爬取新闻的过程中CPU才会飙高,这是正常的,但是当时我上到后台一看100%后只等待了不到一分钟左右的时间看占用率依旧是没有下降就直接去将两个容器停止了运行,所以说我目前并不清楚当前的爬虫进程是否是正处于爬取状态还是常态。所以我考虑的方案是先让GPT给我一套启动这两个镜像的命令,将两个容器启动并且确认轮播图功能正常之后立刻去查看两个容器分别的CPU占用率,等待第一轮爬取结束后再去分别观察CPU的占用率。
1 | 给你一套可直接执行的命令:启动两个容器→确认轮播图→立刻看 CPU→等待首轮结束后再看 CPU。我已按你环境填好值(容器名 NIOHServer、镜像 openharmony-server:latest、对外端口 32776、网络 ohnet、远程 WebDriver selenium:4444)。 |
1 | docker network create ohnet || true |
1 | docker rm -f selenium 2>/dev/null || true && docker run -d --name selenium --network ohnet -p 4444:4444 --shm-size=2g --restart unless-stopped selenium/standalone-chromium:latest |
1 | until curl -sf http://127.0.0.1:4444/status | grep -E -qi '"ready"[[:space:]]*:[[:space:]]*true'; do echo "Waiting for Selenium remote WebDriver on :4444 ..."; sleep 2; done |
1 | docker rm -f NIOHServer 2>/dev/null || true && docker run -d --name NIOHServer --network ohnet -p 32776:8001 --shm-size=1g -e TZ=Asia/Shanghai -e ENABLE_SCHEDULER=true -e BANNER_USE_ENHANCED=true -e SELENIUM_REMOTE_URL=http://selenium:4444/wd/hub -e SELENIUM_USE_USER_DATA_DIR=false openharmony-server:latest |
到这一步之后就是成功启动了。
1 | curl -s -X POST "http://127.0.0.1:32776/api/banner/crawl?use_enhanced=true" |
1 | docker stats --no-stream --format 'table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.PIDs}}' | egrep 'NIOHServer|selenium' |
1 | docker exec -it NIOHServer sh -lc "ps -eo pid,comm,%cpu,%mem --sort=-%cpu | head" |
1 | docker exec -it selenium sh -lc "ps -eo pid,comm,%cpu,%mem --sort=-%cpu | head" |
1 | until curl -sf "http://127.0.0.1:32776/api/banner/status" | grep -qi '"status"[[:space:]]:[[:space:]]"ready"'; do sleep 5; done |
1 | docker stats --no-stream --format 'table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.PIDs}}' | egrep 'NIOHServer|selenium' |
1 | curl -s "http://127.0.0.1:32776/api/banner/mobile" |
1 |
|
上面这就是这次启动服务的控制台全流程,接下来我们去看一下服务的启动情况。
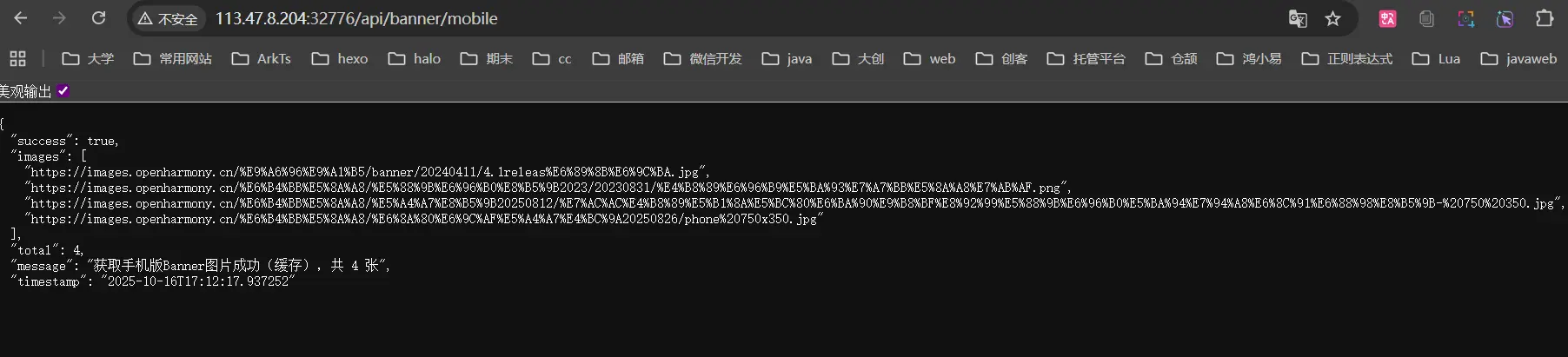
通过接口的访问数据可以看到启动时成功的。接下来就是观察docker的CPU占用率了。
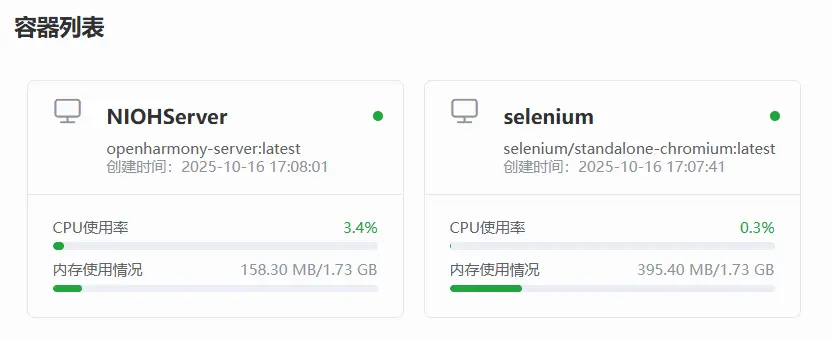
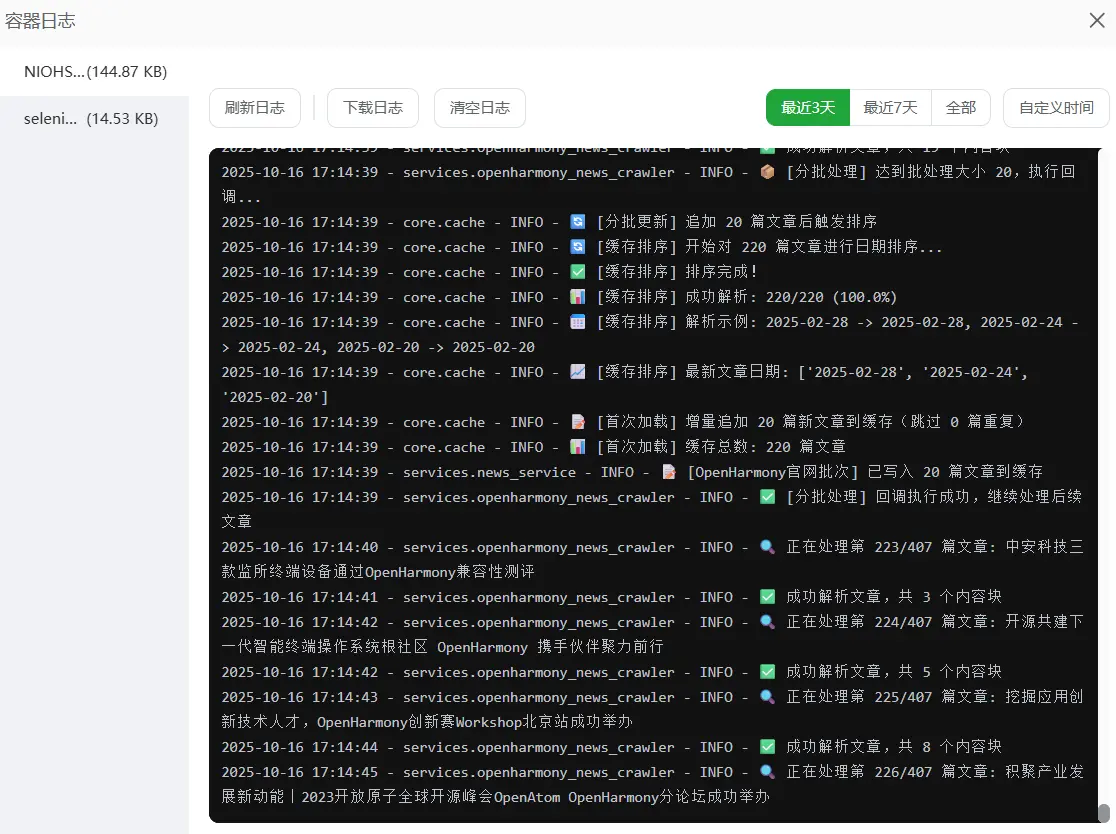
我优先查看了CPU的占用率,发现没有问题,然后又通过日志确认当前就是爬取状态,爬取状态也没有,那为什么会出现飙高吃满的情况呢?这不合理啊。
现在只能说是后悔当时没有第一时间去查看一下容器的占用率是否正常了,应该第一时间留存相关的监控数据以便于分析排查,而不是直接关闭了。
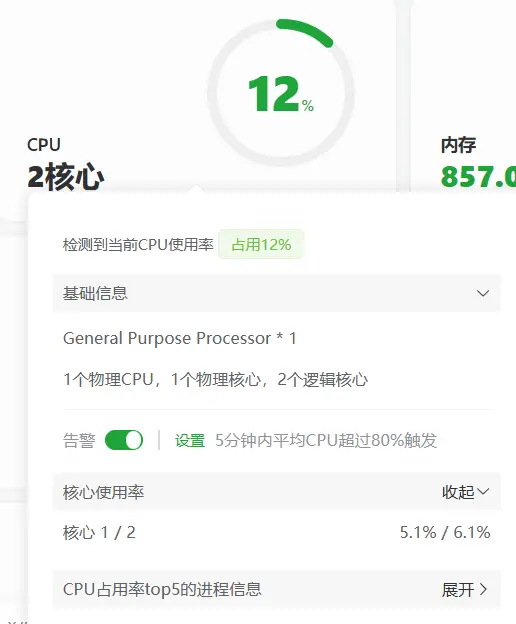
总占用率也是正常的,这还是在同时支持宝塔面板的服务状态下。
持续观察了一会儿发现占用率在持续走低,这更解释不了之前出现的情况了。我猜测可能是我的爬虫逻辑在运行了一段时间之后出现了类似死锁或者是线程池的无限制扩张问题导致了我们的服务CPU占用率飙升。那这就需要等待一天后再来看一看我们的服务器数据了,现在我先让GPT帮我检查一下代码中是否存在这种问题的隐患。并将更新时间拉长到6小时一更新,来减少我的流量开销。
1 | 我做了两件事: |
嗯,看起来Claude留下来的代码还是质量挺高的,GPT给出的建议也都很有道理,这样的话我觉得这三条建议都可以执行。
1 | 已全部执行并提交到 feature/docker-containerization-deployment-issue-4。 |
这一次完整的重新部署之后我像往常一样只间隔了一分钟就去测试获取轮播图的接口发现失败了,吓我一跳,仔细一想好像是因为线程池的总量被限制了,导致爬虫的运行被减慢或者滞后了,所以我多等了几分钟再次进行测试总算是成功了,吓我一跳。
出去吃个饭回来又持续的观察了一段时间发现我后端服务容器占用率始终为0.1%,而Selenium容器占用率始终为0.2%,仅仅是维持着最基础的进程生命周期,完全没有出现任何异常波动,再加上此前GPT已经针对于我们的代码进行了检查和优化,我不能理解为什么那天出现了CPU占用拉满的情况,现在只能是再等一等去进行进一步的观察了。
先让我们向下一步推进吧。
合并分支并完成issue
终于是到了合并分支的时刻了,这场小闹剧已经持续太久了,该让他结束了。
为实现NowInOpenHarmony应用的正式上架,需要完成后端服务器部署、应用商店适配、用户隐私政策制定等关键工作。这是从开源项目到商业化应用的重要里程碑。
这是在第一篇上线笔记中开启的issue,现在该合并并关闭了。
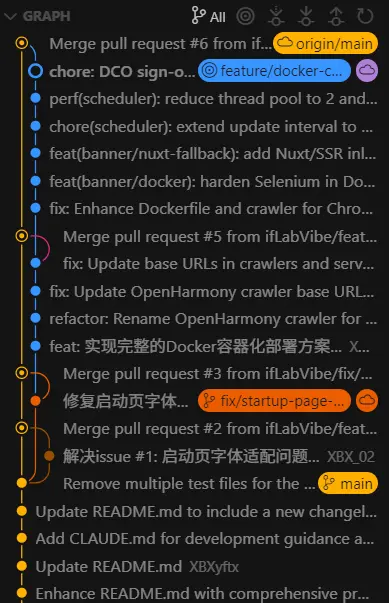
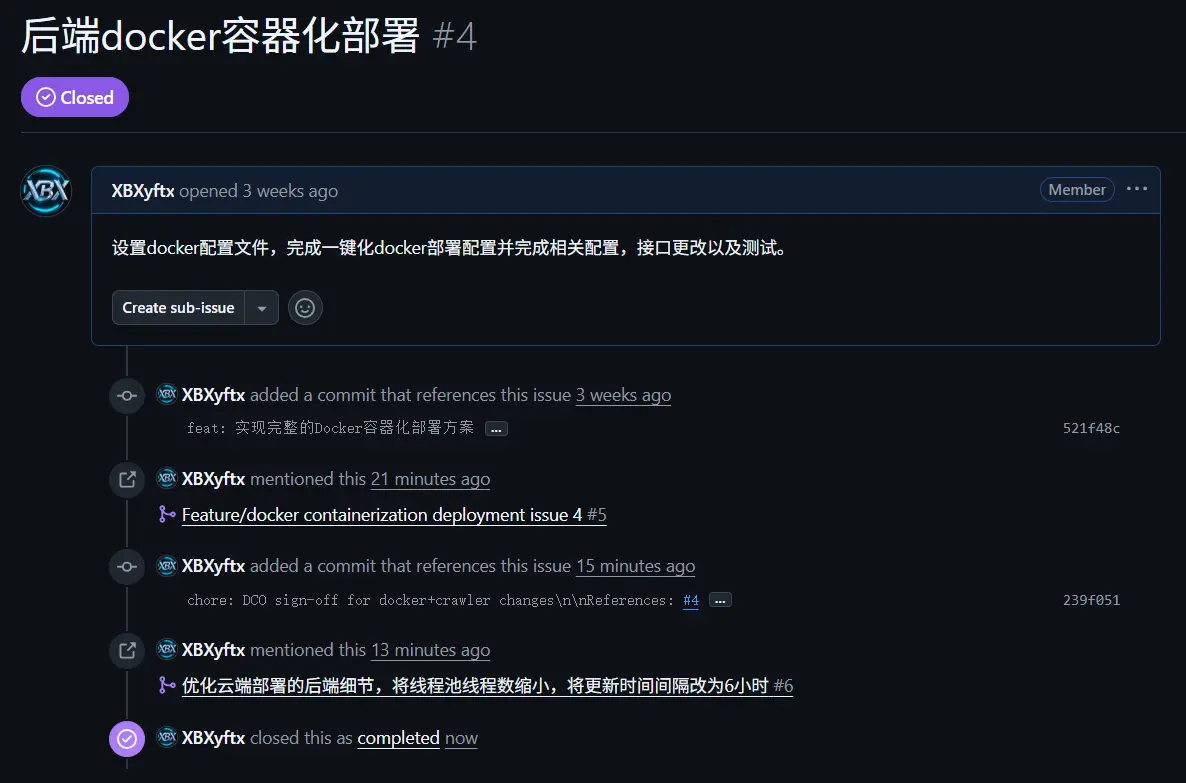
ok,这下舒服了
客户端更换基地址
issue创建
哎,终于是到了这一步了,太不容易了。
相当简单,但依旧规范化,先去创建issue。
此前客户端一致使用的是本地局域网IP,为了方便测试和临时更换服务主机。现在后端成功上线部署,该更换为服务器地址了。
基地址更换
这一步真的简单到极致全要归功去此前我的规范化开发。我将全部常量都统一写到了一个文件中,同时封装了指定基地址的axios网络请求工具,这样我修改一个常量就可以直接实现全局的修改。
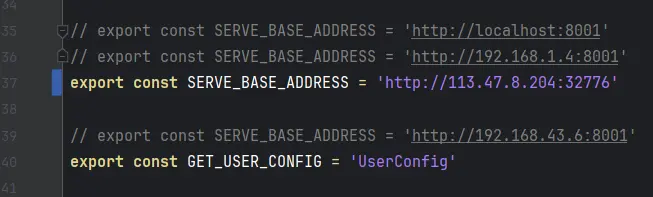
改这一行直接秒掉。让我们测试看一看。
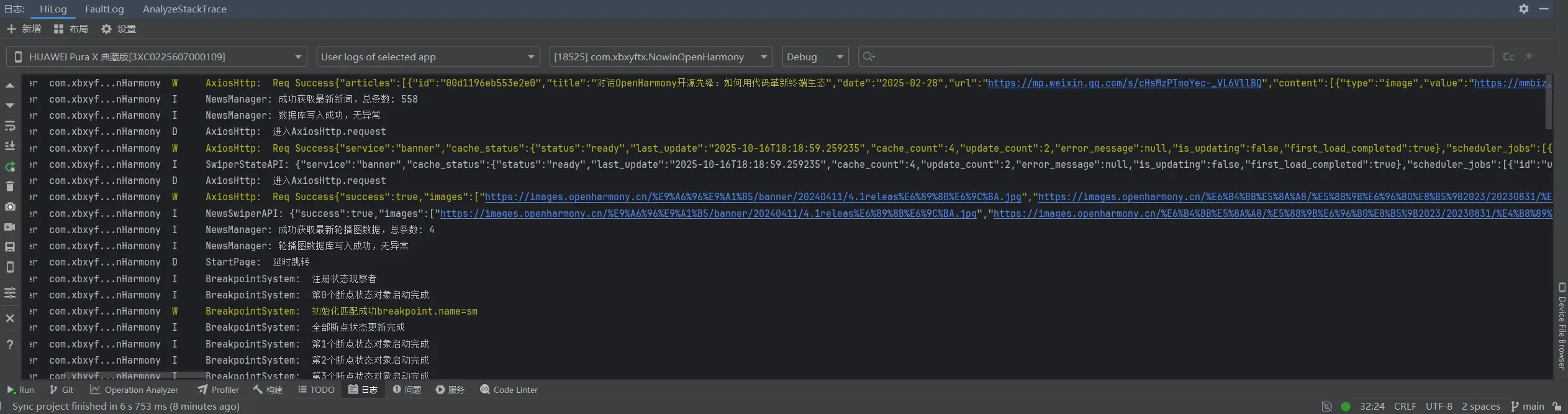
nb直接秒掉!
然后再让我降一下API为API17,来在平板上测试一下,主要是因为我的手机已经升级到鸿蒙6了,但是平板因为太新了没办法升级,所以我只好先暂时降级安装了。
但是我突然发现了新的问题,这好像是虚假繁荣,我没有真正成功的去获取数据,这好像是之前我遗留的数据。我卸载重新安装一下试试。


在重新安装之后我发掘了不对。手机上是轮播图数据异常,而在平板上是完全没有数据了。卧槽我直接炸缸了,我看了日志,发现全是超时,我修改了一下我axios请求工具的超时时长从三秒改到了10秒,发现依旧是超时没有什么区别。我强制自己冷静下来去思考问题可能发生的点,首先我客户端的全流程是在本地都跑通了的,同时在前面的日志截图中也可以看到在第一次测试时轮播图接口是跑通了的,我再去查看了一下我服务器的CPU占用率,发现是正常的,维持在13%的低占用率,理论上响应速度应该是很快的,随后我复制了我常量文件中的IP地址,再拼接上接口的资源路径,在浏览器中进行测试,发现也是正常的。
这时我脑海中闪过一个念想就是从手机和平板的问题表现差异去展开分析。
手机上在重装之前是轮播图通过日志来看是正常的,而新闻看似是正常的实则应该是之前本地测试时的数据,从新安装之后是轮播图明确的超时了,而新闻接口则是正常的。对于平板,我是直接进行了重装操作,在重装之后轮播图和新闻接口都超时了。我仔细观察了一下手机和平板的网络设置差异,当时我手机使用的是流量,平板使用的是校园网,而电脑上用浏览器测试的环境则是连接的校园网但是梯子到了美国的IP。分析一下成功的三个接口:手机上的新闻、电脑上的新闻和电脑上的轮播图,他们的共同点都是并非校园网的代理,我猜测可能是校园网的安全设置阻断了直接使用http对IP进行访问?当然这只是我的猜测,这并非是是确定的原因。
就在我还在思考更加具体的排查方案时,我重新刷新了一次,结果发现两个设备都成功获取数据了,而且网络设置没有进行任何更改(?)
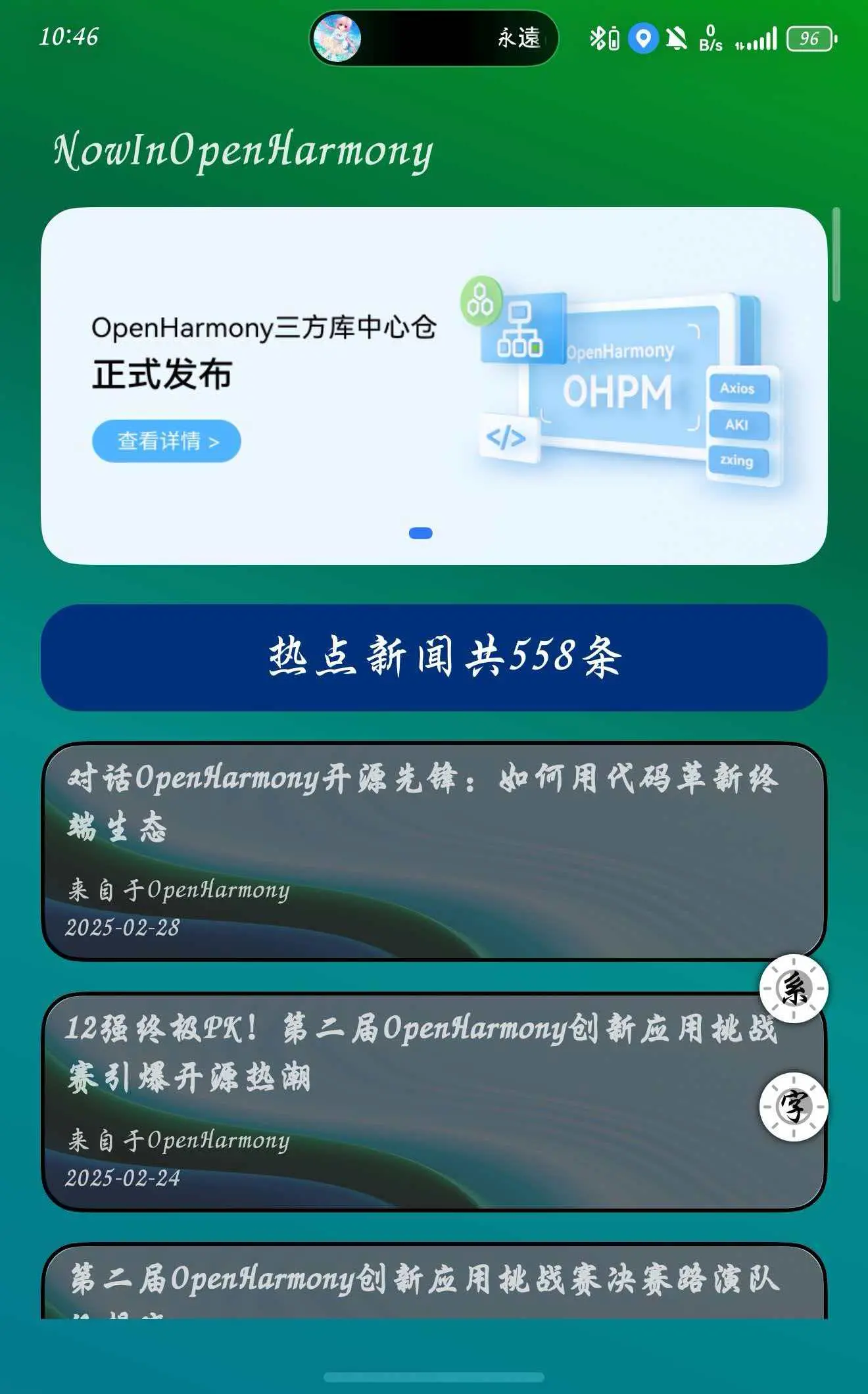
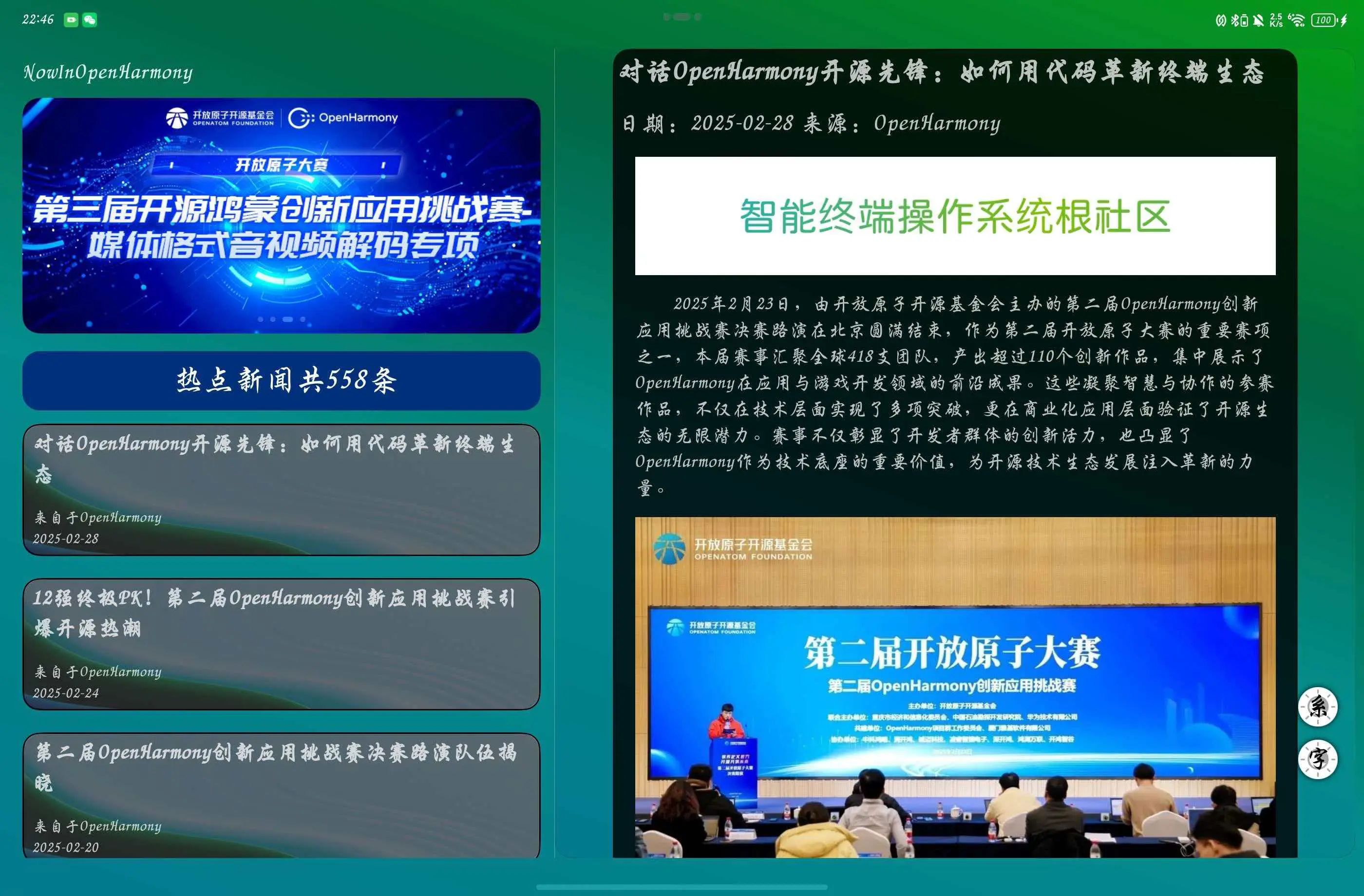
通过多次下拉测试发现好多次报错弹窗,则说明我的后端数据获取依旧不稳定,但是在浏览器访问却是十分稳定的能够获取数据,我不太理解是为什么说实话,感觉这个稳定程度想要上线并不太可能,但至少它上线了,破破烂烂的上线了也是上线了,前后端完整的一个鸿蒙项目。
手动PR尝试
之前一致是用CC或者是codex帮我去进行分支的创建以及代码的推送,这次我向亲手尝试一下创建新分支并且提交pr。这次就先去使用DevEcoStudio自带的git工具去进行操作吧,下一次再去进行命令行的尝试。
分支创建
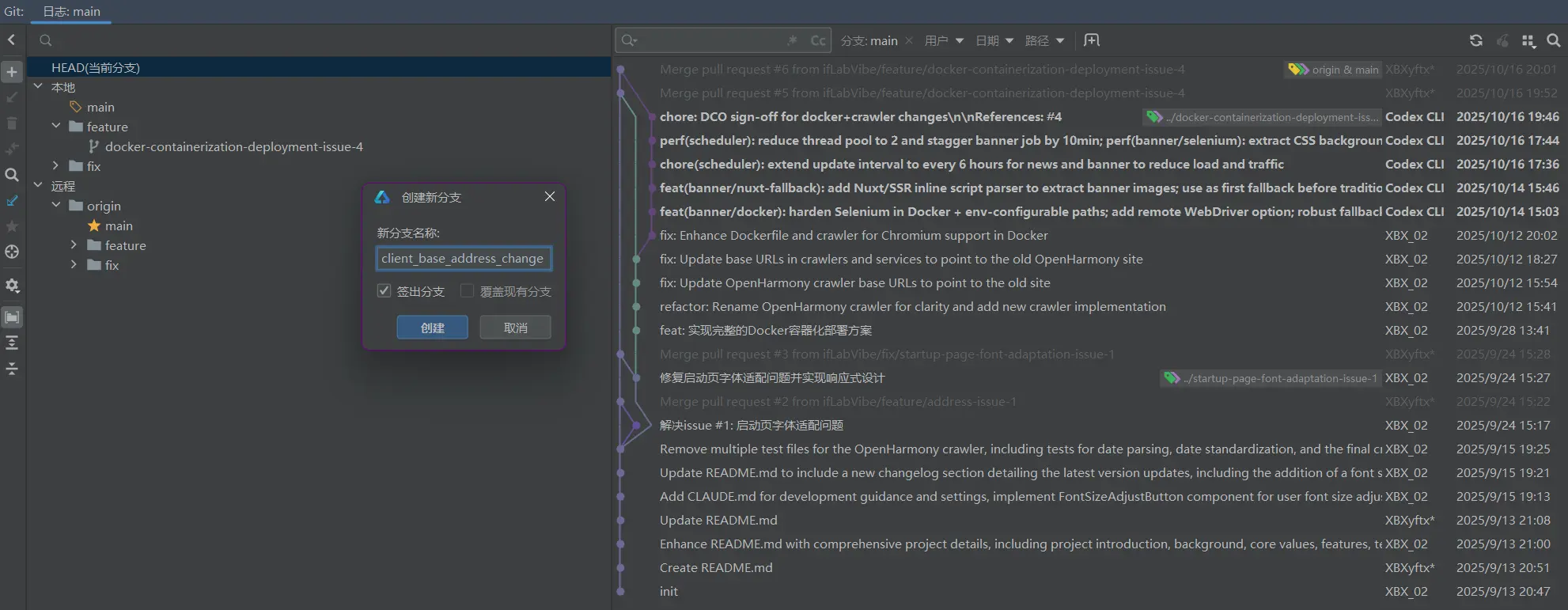
首先通过分支创建功能去进行一个新的分支创建,命名为“fix/client_base_address_change”。
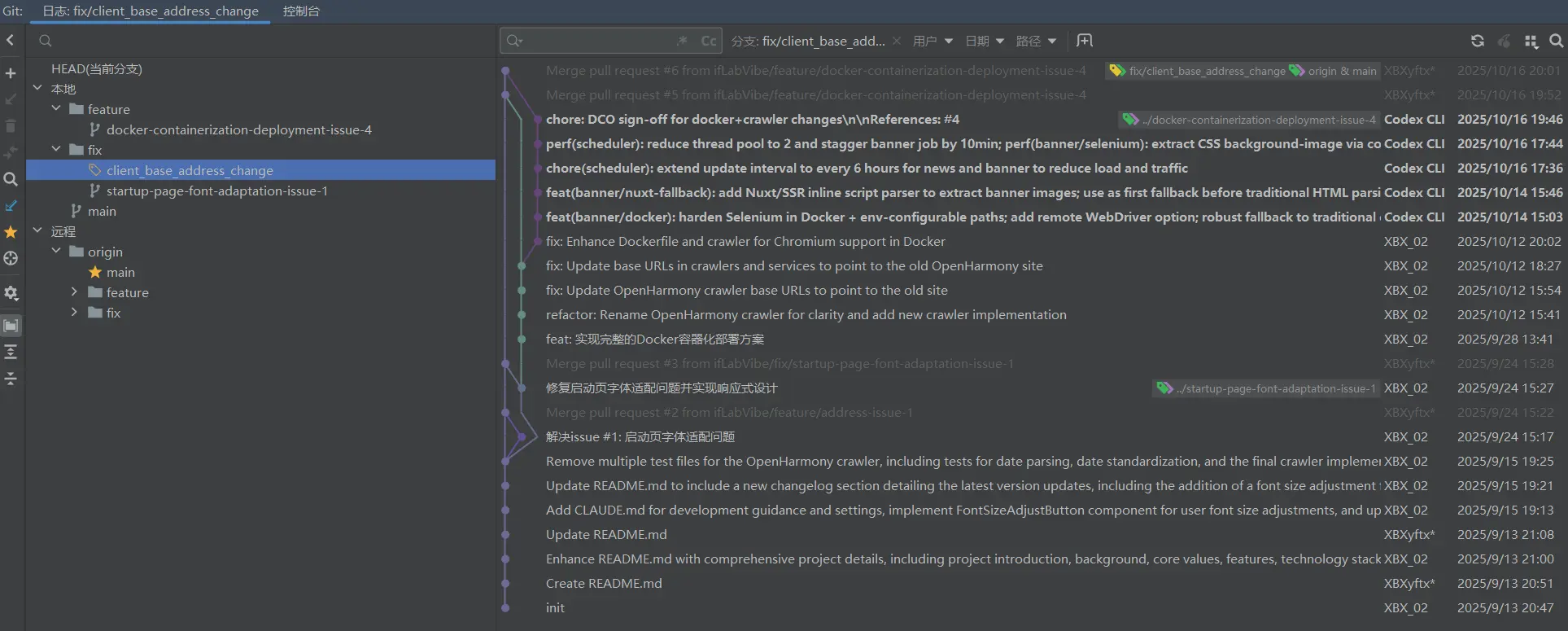
创建成功之后就会像是上图一样,在本地的分支文件夹中多出了我们新增的一个分支。由于这个属于是小的修正,所以我就直接是算在fix文件夹下了。
commit
随后我们就需要在这个分支下去进行commit,要注意一定是当前的文件夹而不是主分支文件夹。
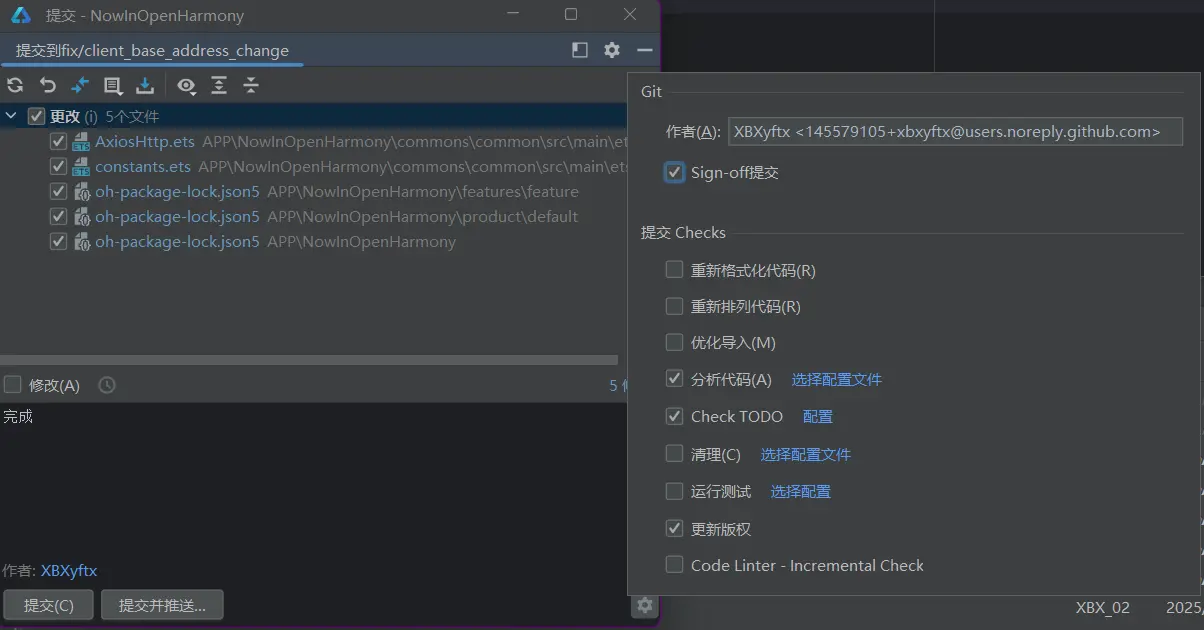
在commit的时候先看一下最上方显示的是提交到哪个分支,随后再去设置中勾选一下签名随后就可以进行commit了。
在提交之后我才想起来我的作者签名好像邮箱用错了,不是我平常用的默认邮箱,所以我就想要撤销这一次提交,撤销之后进行修正并重新进行提交。
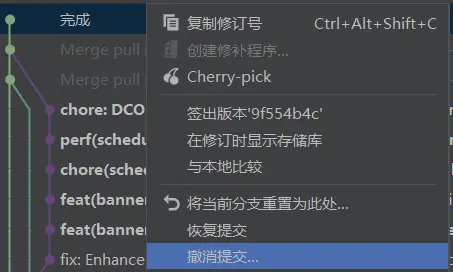
右键选择撤销提交,随后再使用commit进行提交。
在成功commit之后我们就可以看到当前的分支中的commit记录已经领先于主分支了。

分支推送与pr创建
随后我们就可以将当前分支进行推送了。
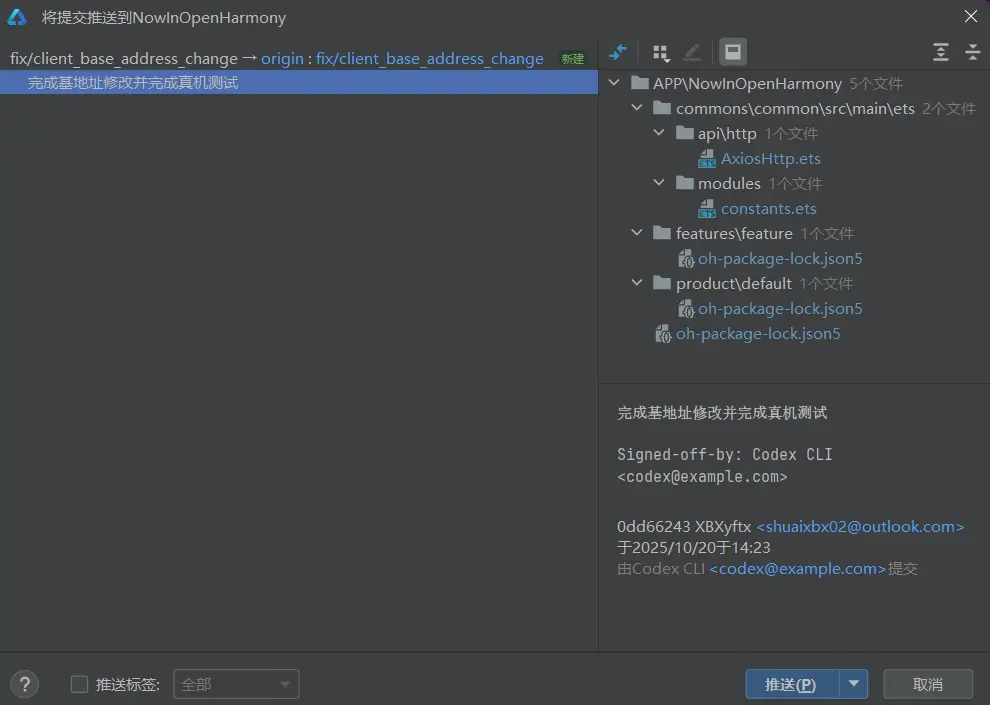
这里可以看到IDE会自动识别到当前本地分支在远程仓库并不存在,这样我们就可以将当前的分支进行创建并推送了。

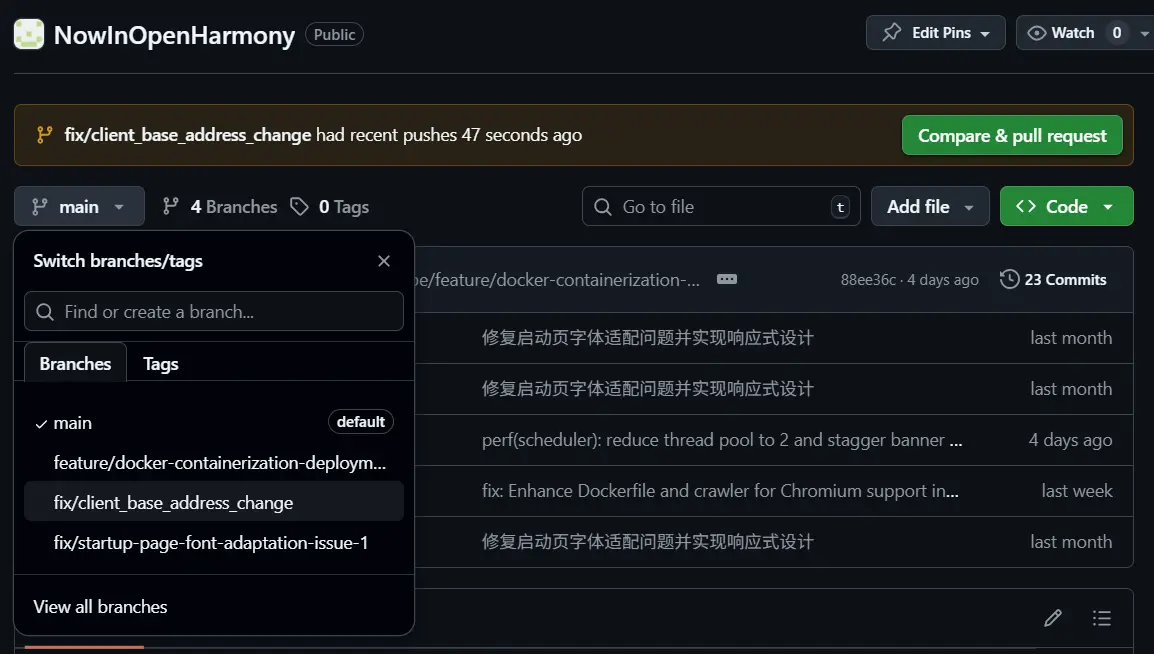
来到GitHub之后就能看到我们刚刚推送的分支,并且GitHub也是自动显示了合并提示,我们接下来点击“Compare & pull request”按钮,去进行pr的创建就可以了。
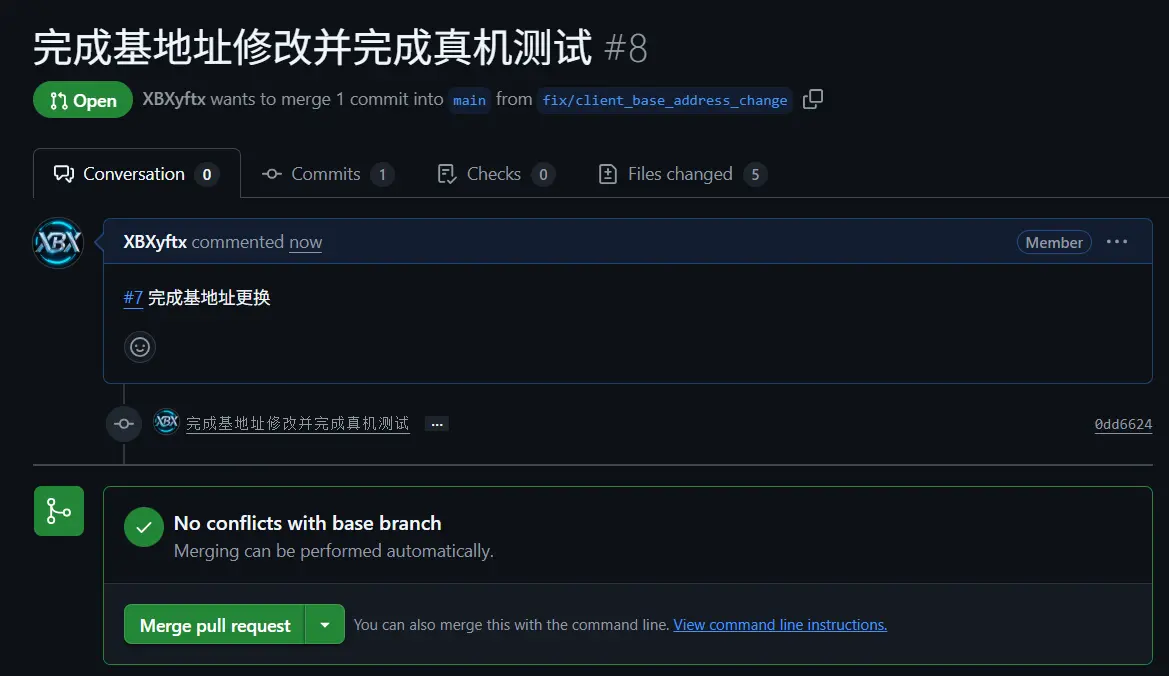
自动审查代码冲突之后,我们就可以进行合并了。





近期进行了不少的优化,也不知道大家感受出来没,加载速度啊、目录跳转稳定性啊巴拉巴拉的。
总之祝大家2026新春快乐!!!